

When Cloudflare sneezes, internet catches the cold
Cloudflare is an internet infrastructure provider that sits between users and applications, handling traffic and security on their behalf.
On 18 November 2025, a big slice of the internet had a bad late morning. Apps stalled. Websites threw generic error pages. People mashed refresh and nothing changed.
Behind many of those failures sat one company in the middle of the path - Cloudflare.
What happened in plain language
From an executive point of view, the shape of the incident is simple:
- A routine internal change to database permissions went live
- An automated job used that database to build a file of “signals” about bots and risky traffic
- After the change, that file suddenly became much larger and more complex
- A core traffic component could not handle the new file and started failing under load
Those failures translated directly into 5xx errors and timeouts for customer traffic.
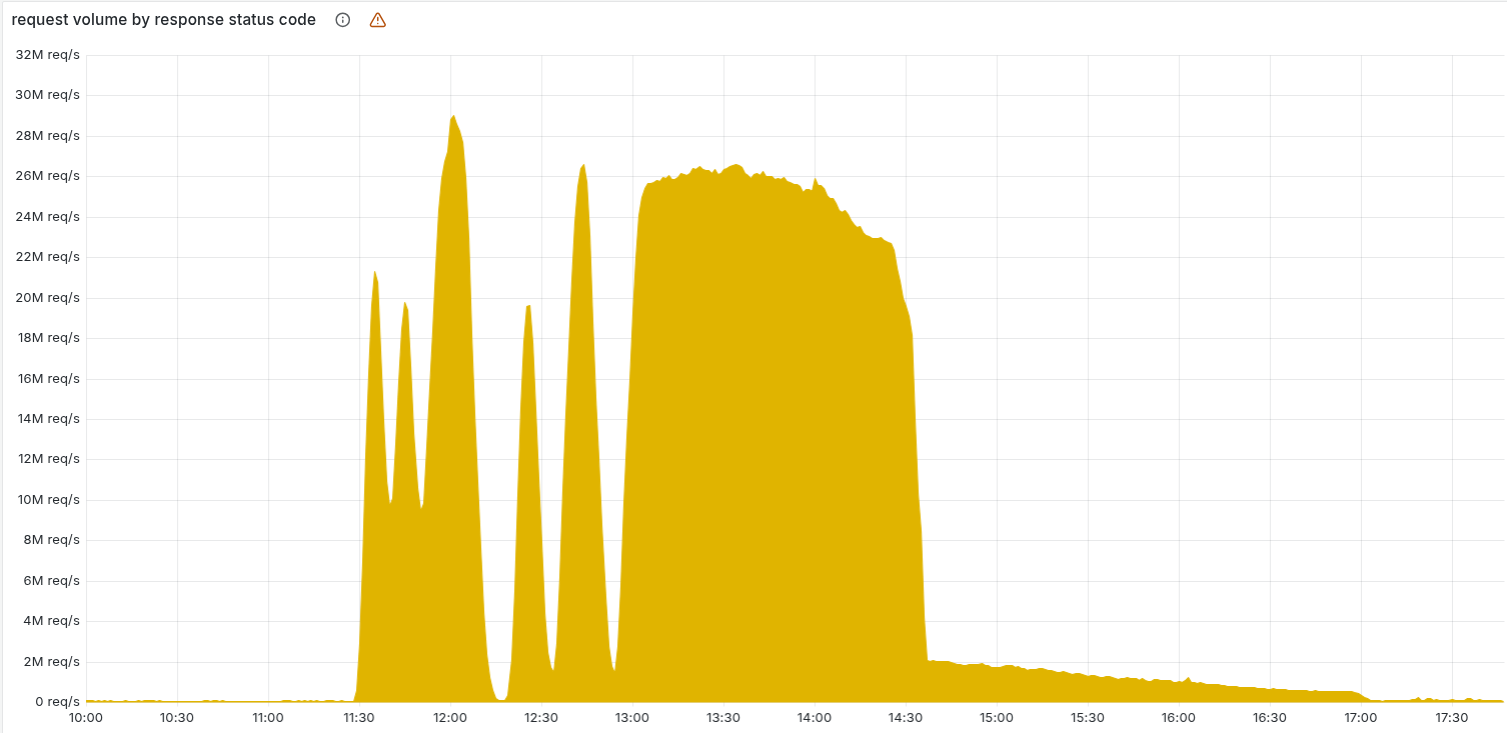
The intense phase lasted roughly 3 hours, from late morning to early afternoon UTC. Cloudflare reported serious internal degradation shortly before noon and declared the main fix in place a little before 15:00 UTC. The long tail of strange behavior and control plane issues stretched the whole event to around 4 hours before things felt normal again for most customers.
How the outage unfolded
You can think of their day in 3 beats.
Early phase - confusion Cloudflare teams saw error rates spike and services slow down across regions. Traffic looked wrong. They had to decide quickly whether they were under attack or dealing with a self inflicted problem.
Middle phase - containment and fixes As they narrowed in on the broken configuration file and the traffic module that choked on it, they shipped emergency changes. That included turning off specific products in certain locations to cut load and risk while they deployed a real fix.
Late phase - cleanup Once core traffic recovered, attention shifted to dashboards and management tools. Customers could reach their sites again, yet some still struggled to log in to the Cloudflare control panel or change settings while internal services caught up.
For users and customer executives, the details of ClickHouse tables and proxy modules are less important than the pattern. A routine internal change quietly mutated a global configuration file, and a hidden limit in a critical component turned that file into a platform wide event.
Why this should worry leaders
Cloudflare carries mission critical traffic for a very large number of companies. When they have a bad 3 hours, payment flows, customer support tools, media, APIs and AI products all feel it at once.
There is a broader lesson here. Many organizations place their most important systems on top of a single global vendor or a single internal platform that behaves like one. That setup looks efficient on a good day. On days like 18 November, the real cost becomes visible.
Relying on one shared provider for the majority of your critical traffic is a fragile bet. The rest of this article looks at what actually went wrong inside Cloudflare, why a similar pattern had already appeared months earlier, and what you can change in your own architecture so one bad file at a single vendor does not freeze your business.
Same pattern in a different subsystem
Key term: Global configuration file is a machine generated file that controls behavior of many systems at once.
4 months before the November outage, Cloudflare had another rough day. Their public resolver 1.1.1.1 - the phone book many devices use to find websites - went down after a bad change in how they deploy network configuration.
Those two incidents involved different products, yet they share the same underlying pattern. In both cases a global configuration file quietly changed shape, and the systems that depended on it had almost no protection when that happened.
July: the resolver that blinked
In July, Cloudflare maintained a global routing model that decided which data centers should serve which IP prefixes. An older deployment system turned that model into concrete router configuration.
A small mistake landed in the model in a non production context. For a while it had no visible effect. When a new site was wired into the system, the model recalculated and produced a very different output. The legacy deployment path took that big diff and pushed it to routers in one move, without asking if the change looked unusually large or risky.
The result was simple from the outside. Queries to 1.1.1.1 failed in many places at once because routers applied exactly the configuration they received.
November: the bot brain that choked
In November, the central actor was a feature file for Bot Management.
Cloudflare scores traffic using many signals. An internal job reads metadata from ClickHouse, turns it into a feature file, and ships that file to the FL and FL2 proxies in front of customer applications.
A routine permissions change in ClickHouse altered what the job could see. The next run produced a much larger and more complex file. The FL2 module that reads it had internal limits on what it could process. The new file exceeded those limits and triggered failures, so a single file influenced behavior across a significant part of the fleet.
The shared failure skeleton
Seen side by side, the same skeleton appears:
- One global configuration file shapes behavior for a critical service
- A routine upstream change - adding a site, adjusting permissions - triggers a new version
- The new file has changed dramatically (compared to the last working set)
- Consumers of the file trust it and offer little protection when it goes out of bounds
Different teams, different stacks, identical structure.
What a diff guardrail would have done
Key term: Diff guardrail is an automated check that compares a new configuration against the previous one and blocks changes that look unusually large or risky.
Picture a simple rule around that bot feature file:
- Each new file is compared to the last one
- If size, number of features, or other key metrics jump beyond a defined range, the pipeline rejects the file
- The system keeps serving the last known good version and asks an engineer to review the change
In November the file that broke FL2 was significantly larger than its predecessor. A guardrail like this would very likely have stopped it from reaching the fleet. Bot Management would have kept using the older file. Engineers would still need to fix permissions and generator logic, yet customers would have experienced a normal day.
The lesson from July pointed directly to this kind of protection for every global configuration pipeline, not only routing. November showed that this insight had not yet been applied across the wider platform.
What Cloudflare will fix - and what is still missing
Key term: Remediation plan is the set of follow up changes a company commits to after an incident, aimed at reducing the chance and impact of similar failures.
After the November outage, Cloudflare published a detailed explanation and a list of changes they plan to make. That transparency matters. When a provider sits in front of so much mission critical traffic, customers need to see more than a short apology and an uptime graph.
Read in plain language, their remediation plan has 4 main ideas:
- Treat internally generated configuration as carefully as external user input
- Make the Bot Management module handle bad files without crashing core traffic
- Strengthen kill switches so risky modules can be turned off quickly
- Limit how much logging, debugging, and core dumps can hurt performance during an incident
Each of these points pushes the platform in the right direction.
Treating internal configuration as untrusted input is a big mental shift. Many teams still see generated files as “our own data” and assume they are safe by default. Cloudflare is now saying out loud that their own config can be just as dangerous as anything a customer sends them. That mindset, if applied consistently, reduces the number of hidden sharp edges in a complex platform.
Improving Bot Management failure behavior also matters. In November, a single bad file triggered panics in code that sits directly in the hot path for HTTP traffic. The remediation aims to ensure that if the bot feature file is malformed again, the module degrades gracefully or steps aside, and basic request handling continues. That kind of separation between optional intelligence and essential traffic handling is healthy in any large system.
Kill switches sit in the same category. When a provider operates at Cloudflare scale, operators need the ability to disable a misbehaving feature across the fleet with one clear action. If that switch exists and is safe to use, an internal error in something like Bot Management can be cut out of the request path while teams debug in the background.
Their plan to cap observability overhead belongs here as well. During big outages, log streams, metrics and core dumps can eat CPU and storage. The tools that should help resolve the problem can turn into an amplifier. Adding hard limits and smarter backoff protects precious capacity when things are already going badly.
All of this is positive. It shows that Cloudflare engineers understand the specific weaknesses that turned a broken file into a global problem.
The gap sits at a different level. The remediation language focuses on Bot Management, observability, and nearby systems. There is no visible, explicit commitment that says: “Every system at Cloudflare that generates configuration capable of impacting a large share of traffic will now be brought under a common safety pattern.”
July and November both featured global configuration files with weak guardrails. Seeing that shape twice in a year raises a natural question for any customer that relies on Cloudflare for core business traffic: are these lessons now being encoded as company wide standards, or only as fixes in each affected product?
If you bet your own mission critical systems on a single global vendor, that question is not optional. You are effectively tying your resilience to how deeply that vendor learns from its failures, and how quickly pattern level insights move across their platform.
Turning Cloudflare’s bad day into your learning moment
Key term: Global platform is any shared system that many teams or customers rely on to move traffic or data.
Cloudflare’s outage is a warning shot for anyone who runs or depends on a global platform. The pattern behind it is not unique to public CDNs. Internal API gateways, security platforms, feature flag systems, even central data pipelines can behave in very similar ways.
If your company has one or 2 platforms that everything else leans on, you are closer to Cloudflare than you might think.
Spot your “mini Cloudflares”
You do not need a large project to start learning from this incident.
First, identify your own global platforms. In a short conversation with your leadership team, list the systems where a mistake would ripple into many products at once. Typical candidates:
- API gateways and edge proxies
- Central authentication and access systems
- Feature flag or config management services
- Internal DNS or traffic routing layers
For each one, capture just 3 facts: what it controls, who owns it, and which business capabilities would stall if it went offline.
This alone gives you a clearer view of where you have concentrated risk on a single internal platform or a single external vendor.
Ask sharper questions about guardrails
Next, pick one or two of those platforms and dig one level deeper. You do not need diagrams or deep dives. You need direct questions.
For the platforms that ship machine generated configuration or models, ask:
- How do we know when a new configuration looks unusually large or different from the previous one
- Is there any automated check that can block a risky change before it reaches the whole fleet
- If a generated file is broken, what does the consuming service do
You are looking for simple signals: clear owners, clear checks, and a clear idea of what happens when those checks fail.
If the answer relies heavily on “we trust our processes” or “we review changes manually”, your situation is closer to Cloudflare’s pre outage world than you might like.
Add one practical safeguard
Finally, choose one global platform and sponsor a small, concrete improvement.
Good candidates:
- A basic diff alert on a critical config file
- A feature level switch that lets operators disable a risky module while keeping core traffic alive
- A short exercise where a team walks through how they would respond if a bad config version started to roll out
The exact move matters less than the fact that it is repeatable. The goal is to create a pattern that other platforms can copy later.
Do not hand your fate to one vendor
Many companies now place most of their mission critical traffic behind a single external provider, and then layer their own global platforms on top of that. Efficiency and simplicity look attractive when everything works. On a day like 18 November, the downside becomes obvious.
You may not be able to remove single vendors or single platforms overnight. You can still reduce blind trust. Understand where your risk is concentrated, push for visible guardrails around global configuration, and be deliberate about the bets you place on any one provider or platform.



